






Are we headed for a dystopian sci-fi scenario where machines make all our decisions? In this second instalment of our two-part series, we discuss what it means to be fair in ethical machine learning, the surprising ways bias creeps in and why it’s so important to keep humans in the loop.
Governments and businesses around the world are increasingly concerned with ensuring the fair and ethical use of machine learning. Most strikingly, in the United States, Facebook and Twitter have taken some actions around the recent presidential election to flag or remove disinformation – setting aside the question of whether their responses are sufficient and proportionate – notably Twitter’s removal of Donald Trump’s account.
In Australia and New Zealand, we have also seen significant developments in government, including some relevant local developments:
- In July 2020, New Zealand released its Algorithm Charter for Aotearoa New Zealand, which is essentially a call to action for public agencies to provide New Zealanders with the confidence that algorithms (and AI) are being used sensibly and ethically. We have discussed this in a separate article, Algorithm Charter for Aotearoa: six things to be doing now
- In August 2020, the NSW Government effected the NSW AI Ethics Policy to guide the use of AI in the public sector. This defines mandatory ethical principles for the use of AI by NSW government agencies.
The right strategy – where can organisations begin?
For boards and management keen to address the issues of fairness in their data and technology, first, it’s critical to ensure human oversight to implementing ethical processes and a good governance structure. This will help establish appropriate people with responsibility for the fair application of machine learning, who can take action if problems arise. After that, there are four key considerations:
- Fairness – Is your system as a whole fair?
- Privacy and data ownership – Do you have permission to use the data for this particular task? Are you at risk of exposing private information?
- Transparency – Do the users of the system and people affected by decisions or outcomes from the system understand why particular decisions are made? For high-stakes decisions, interpretable models may help (see our previous article, Interpretable machine learning: what to consider)
- Accountability – How can those impacted by decisions understand and challenge them? Is there an avenue for redress? Who is responsible for the appropriate use of the algorithm?
What do we mean by fairness anyway?
Drawing on the parallels with Just War Theory (discussed in Part 1 of this series), fairness means that the overall action is justified and the way we implement it is ethical. Furthermore, many actions have positive and negative impacts so it’s important to also consider the principle of proportionality – are the benefits proportional to the possible harms?
Thus, the first step is to decide if you are justified in using machine learning at all. Assuming you consider that you are, then the next step is to ensure that the process as a whole is implemented fairly. This in turn means you need to decide how fairness is defined in your particular context.
Fair is not fair
At a high level, we might say fairness means treating everyone equally. But if we drill down into details, what do we really mean by this? Let’s suppose we want to make a decision for a group of people and we want to treat men, women and non-binary fairly, that is, we don’t want to discriminate on the basis of gender. Suppose also that we plan to use a process to select some people for assistance to combat disadvantage suffered by them. In order to be fair for all, does fairness mean that:
- We give exactly the same assistance to each individual? (Also known as formal equality)
- We give differential levels of assistance so that, overall, everyone ends up in a similar position after the intervention? (Substantive equality)
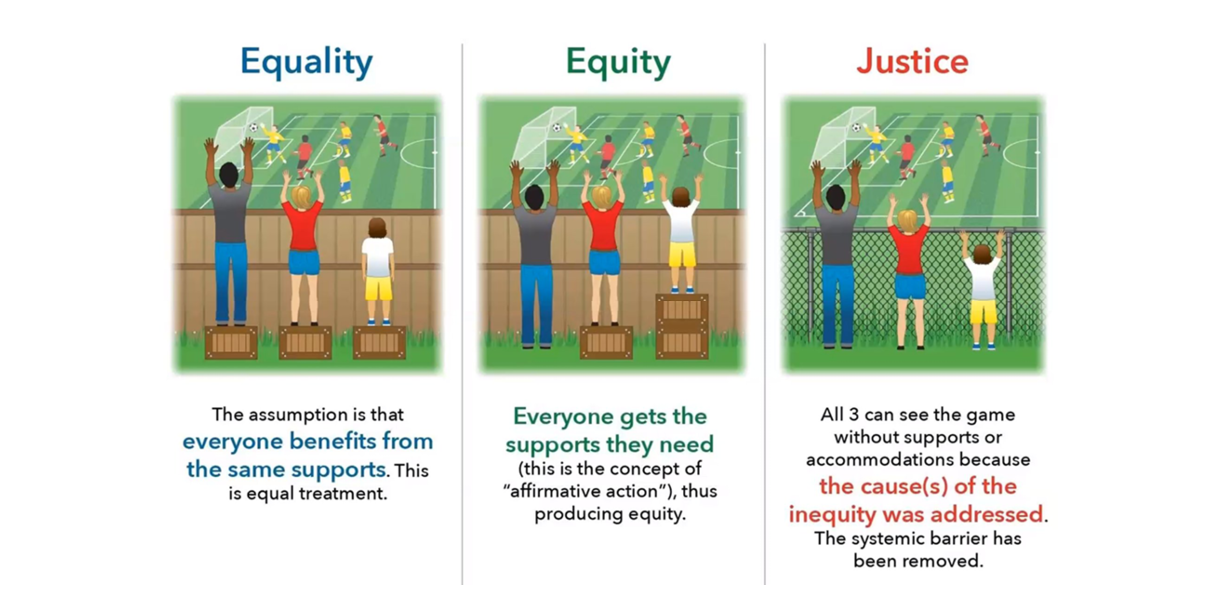
‘At a high level, we might say fairness means treating everyone equally … ‘
The answer is it depends on our aims and what we want to achieve. Fairness is very context dependent. What is right in one situation may not be the fair choice in another. For example, if a bank is considering whether to give someone a loan or not, then most of the time we’d probably view equality of treatment between genders as equitable. However, often gender is important and differential treatment might actually be a fairer option than identical treatment for all.
A Swedish lesson
In her book Invisible Women, Caroline Criado Perez gives a fascinating example where snow-clearing in Sweden was found to discriminate against women. A gender-equality initiative in 2011 meant that the town of Karlskoga in Sweden had to evaluate all policies for gender bias. No one had considered a gendered aspect to snow-clearing before in the town but once they did they realised that the usual snow-clearing policy (starting with major traffic arteries and working down to pedestrian and bicycle paths at the end) did affect men and women differently.
The difference was in their travel patterns. Basically, men are more likely to drive in a twice-daily commute (pre-COVID-19, anyway), while women are more likely to make frequent shorter journeys closer to home and on foot, or by public transport, due to their greater share of unpaid care work of children and the elderly. The town councillors decided, on the basis of this difference, to prioritise clearing the footpaths and public transport areas – it’s much harder to walk through snow, especially with a buggy or pram than to drive through it.
The story doesn’t end there, though, because what actually happened is the authorities ended up saving money – wintertime hospital admissions for injuries were dominated by pedestrians falling in icy conditions, so these were greatly reduced. While this isn’t an example of a machine learning decision process, it does illustrate some of the nuances in considering the question of fairness for different groups.
‘No one had considered a gendered aspect to snow-clearing before in the town … ‘
Defining fairness at the outset
Getting back to your problem at hand – how to decide if your system is fair: agreeing with stakeholders what exactly you mean by fairness for the particular process or system is a critical conversation to have early on. It’s important to cast the net far and wide to try to consider as many relevant issues as possible. The answer will depend on the context and usually there will need to be some trade-offs. Unsurprisingly, there are no hard-and-fast rules for determining what type of fairness to use, but these rules of thumb may be helpful:
- If your process is assistive, then you should be concerned with errors of exclusion – you don’t want to exclude people from receiving help in a biased way
- Conversely, if your process is punitive, then including people in error usually leads to greater harm.
Fairness through unawareness
Often people suggest ‘fairness through unawareness’ as a quick fix to removing bias. This is where the modelling process ignores the protected characteristic. There’s a subset of cases where this will work, but you still need to collect information on the characteristic so that you can review the process for fairness. However, a lot of the time it will fail – even if you have concluded that the fair thing is to treat genders equally, omitting gender from your model may not achieve this – other variables may act as proxies for gender.
Of course, fairness through unawareness is unsuitable for cases where the ethical action is to take account of differences in gender. An example of this is in medical diagnoses, where diseases can present differently in males and females.
But models are objective, aren’t they?
One argument put forward in support of using algorithms for decision-making is that they are more objective and remove subjective human decisions. The trouble is that models are built on data – essentially, they identify patterns in the input data and use these patterns to make predictions about new data. While this can be valuable when the input data is ‘clean’ and free from bias, if we feed biased data in, then the model will perpetuate these biases.
Unfortunately, we know the world has systemic biases – if algorithms are applied at scale, they can do significant amounts of harm. Cathy O’Neill provides many examples in her book, Weapons of Math Destruction, including the United States example we mentioned in Part 1, where a US magazine unintentionally altered the tertiary education environment in the 1980s. The Swedish example, above, highlights the nuances of bias – often the presence of biases are not readily apparent.
The problem with patterns in crime
One of these concerns predictive policing machine learning tools, which are frequently used in the US. Some look at patterns of crime in an area and can be useful for preventing burglaries and car theft.
However, if the systems are set up to include more minor or nuisance crimes, then fairness problems can creep in. These types of crimes generally go unreported if there are no police present to see them. While they can occur in all areas, they are usually more frequent in impoverished districts and this sets up a destructive feedback loop.
More police are directed to these impoverished areas, in turn detecting more minor crime, which feeds into the model to direct even more police to the area. Those affected get caught up in the penal system, often for crimes that are ignored or undetected in less impoverished areas.
A testing time ahead
So while we live in an imperfect world, we need to consider biases in the data and structural barriers in society, and take action to address these. This isn’t easy – as illustrated by Ofqual’s algorithm for allocating A-level grades (high-school final exams) in the UK in 2020, following exam cancellation due to the COVID-19 pandemic. As discussed in our recent article When the algorithm fails to make the grade, it appears that a sincere effort was made to produce a fair process, which did tick many boxes. However, it fell short in significant areas and the backlash eventually led to the algorithm-awarded grades being scrapped.

‘Professor Lokke Moerel, of Tilburg University, the Netherlands, likened AI to the first cars … ‘
Other concerns that go hand in hand with fairness
Fairness tends to dominate discussions about ethical AI, but the other aspects of an ethical process are also important. For example, inappropriate use of data is a significant breach of trust and may possibly breach regulations as well.
Transparency is critical because it allows you to understand why your models make certain predictions. Not only is this important for sense-checking of results but it’s also important when looking at fairness at an individual level. It can help you identify the source of unexpected results. In a wider sense, it also includes being very clear about what the algorithm can and can’t do and when algorithm results should be supplemented by human judgment.
Finally, accountability is important to ensure a pathway is set out for decisions to be challenged and changed where appropriate. Dystopic fictional futures in which algorithms make all decisions should belong in science fiction – keeping humans with real agency in the loop is important. The reality is different, however, and not confined to fiction – we already see numerous examples of ‘the algorithm says so’. For instance, earlier this year, an African American man in Michigan was wrongfully arrested and held in a detention centre for nearly 30 hours after facial recognition technology incorrectly identified him as a suspect in a shoplifting case.
We’ve spent ages coming up with the fairest process we could think of, so we don’t have to worry about it again. Right?
Wrong. No matter how hard you try, there will be some undetected bias in the model, or some unanticipated unfairness or unintended harms. You’ll need to closely monitor the outcomes of your system and identify ways in which it can be improved. This could be anything from minor changes to going back to the drawing board.
In a presentation to the 2020 European Actuarial Academy conference on data science and data ethics, Professor Lokke Moerel, of Tilburg University, the Netherlands, likened AI to the first cars, which didn’t have brakes or other safety features. It was only after people started driving them for a while when the need for brakes was realised. As time went on, we iterated over more and more safety features. The same too with machine learning and big data – we need to be aware when we deploy solutions that there will be failings and shortcomings, and we must be prepared to regularly address these and improve processes and systems in the interests of all those in our society, particularly the disadvantaged.
A systemic approach to regulating machine learning and artificial intelligence
The first-car analogy extends further. Professor Moerel also noted that the infrastructure to support the first cars, such as traffic systems and the wide use of tarmac roads, was not present but developed over time. Likewise, machine learning infrastructure is also missing, specifically, regulating the use of machine learning to ensure it’s used in an ethical and beneficial way, rather than used by a small number for their advantage at the significant disadvantage of the majority. It’s important we all continue to have this conversation together, and take action at individual, organisational, governmental and global levels to bring about a future where AI is used to help not hinder.



