


We need to talk about interpretable machine learning and embracing robust experimentation

How can machine learning models be easy to understand and accurate? Why is it dangerous to listen to the HIPPO?
Amid the glacial wilderness of Anchorage Alaska, some of the greatest minds in the data world gathered to talk hot topics at the 25th Association for Computing Machinery Special Interest Group conference on Knowledge Discovery and Data Science – or KDD for short. Peter Mulquiney, Jonathan Cohen and I braved the wild surrounds to take in the lively discussions.
KDD bills itself as the premier interdisciplinary conference in data science and, judging by the list of attendees and impressive talks at this year’s event, that description felt pretty apt. Speakers from Google, Baidu, Alibaba, Amazon, Apple, Microsoft, NASA, LinkedIn, Facebook and many leading universities entertained the 3,500 visitors from around the world.
Truly interdisciplinary, the streams covered several techniques. These ranged from deep learning, reinforcement learning, natural language processing and time series analysis to causal discovery, explainable AI, adversarial learning methods, graph theory, automated machine learning and recommender systems. Their applications were in areas spanning health, transportation, conservation, social impact, epidemiology, education, ecommerce, marketing and finance to name a few.
Among all of this detail and choice, some main themes emerged, including the continual rise of deep learning, the incredible scale and use of data science in the leading Chinese tech companies and the importance for AI decisions to be ethical and fair. Above all, two themes dominated much of the discussion and are relevant to much of what we do: the need for interpretability in machine learning, and the importance and difficulty of establishing causal relationships.

For some, the conference was polarising
The need for interpretability in machine learning
A common, and often genuine, criticism of many machine learning solutions is their ‘black box’ nature: users feel unable to adequately explain or interpret the outputs they produce. This lack of understanding has implications for fairness and trust in the model, potentially hiding unwanted or erroneous relationships the model has learned and which may have significant consequences for end users. Tackling the problem of interpretability is an active and popular field of research, as shown by the numerous talks on the subject – including a full day of (well-attended) tutorials and workshops dedicated to explainable AI!
Keynote speaker Professor Cynthia Rudin, of Duke University in North Carolina, stood out among the talks of new and varied deep learning architectures and implementations. She chose instead to ask the question, Do simpler models exist and how can we find them?, arguing that the trend toward more complex models is neither necessary nor helpful. Presenting her research, she showed the conflict between interpretability and performance – where either the models are accurate but difficult to make sense of, or easy to understand but prone to error – is not as stark as many assume, and how simple-yet-accurate models can be found for many problem domains.
This sentiment was echoed by Rich Caruana, of Microsoft Research in Washington, in his talk Friends don’t let friends deploy black-box models: the importance of intelligibility in machine learning. He discussed the need for model interpretability, particularly in the presence of confounding variables. Citing examples of machine learning failures in the health sector, he emphasised the importance of understanding the relationships being learned by the model, and ensuring these are reasonable and reflect the available domain knowledge – and correcting where they don’t! He promoted the use of simpler model structures, where these relationships are more easily observed and modified, as a more interpretable and accurate approach.
For those of us familiar with the humble yet powerful generalised linear models, these arguments in favour of interpretable and controllable models felt all too familiar – a refreshing vote of confidence for the value of this accurate modelling approach. Deep isn’t always best!
The importance and difficulty of establishing causal relationships
Causal modelling was a hot topic at KDD 2019. Data is increasingly used to optimise business decisions in areas such as personalised marketing, next-best action, product design, pricing and user experience. Behind these decisions is a simple question of causation: given a set of competing options to choose from, which one will lead to the best outcome? The statistically sound approach would be to answer this through randomised controlled experiments (also known as A/B tests), when possible. Speakers from Microsoft, Outreach, Snap Inc. and Facebook discussed the importance, challenges and pitfalls of conducting these kinds of experiments individually and at scale.
Providing a great overview of the topic, guest speaker Ronny Kohavi shared his experience from 14 years leading Microsoft’s experimentation team and, before that, as head of Amazon’s data mining and personalisation team. In his talk, Trustworthy online controlled experiments and the risk of uncontrolled observational studies, he discussed the dangers of relying on opinion or non-causal analysis as the basis for change – such as HIPPO (highest paid person’s opinion), observational studies and natural/non-randomised experiments.

50 shades of blue? Experimentation can be very revealing
Humans, he concluded, are generally poor at assessing the value of ideas and, to illustrate the point, Ronny shared some Microsoft statistics: hundreds of new ideas are tested – using randomised controlled experimentation – every day at Microsoft, with the belief they will add value, and yet only one-third of these meet even their most basic targets and only 0.02% significantly improve upon their most important engagement metrics.
As further proof of the value in randomised controlled experimentation, he highlighted a well-known event at Google a few years ago. After noticing two different shades of blue font were being used for a sole purpose, the data science team decided to unify and adopt a single colour. To determine which colour drove the highest user engagement, they tested 41 different shades of blue. The demand for data analysis in testing such ‘miniscule design decisions’ – seeming to favour engineers over designers – was cited by Google’s head of design at the time as a reason for his resignation. Yet the experiment led to a US$200 million boost to annual ad revenue.
With many examples why randomised controlled experiments should be conducted, Ronny also discussed the challenges and pitfalls they present. One key challenge was gaining agreement across Microsoft, he said, on what ‘success’ truly means, in the form of an Overall Evaluation Criteria (OEC).
Defining the right OEC is critical, he added, otherwise the decisions made will not be optimising the overall success of the business. A good OEC should rely on short-term metrics, which allow it to be readily observed, and those metrics should be predictive of longer-term value (such as customer lifetime value).
Other pitfalls often lie in the execution of experiments, with Ronny highlighting the need to be wary of common issues such as sample ratio mismatch (an unexpected difference in treatment and control population sizes), novelty effects and poorly designed metrics. At Microsoft, A/A tests (where the treatments are identical and expected to yield identical results) were proposed to safeguard against flaws in experiment design and measurement. In addition, a broader set of robust monitoring practices were carried out, including raising alerts when things look too good to be true and not just when they are going poorly.
So what does all this illuminating discourse mean in practice? Here are our KDD takeaways that we’re going to be applying back home:
- There is value in simplicity. Strong arguments support using simple, interpretable models in practice. Not every problem needs the latest deep-learning solution. Interpretable models can be deciphered and explained. They also provide insight and trust, the value of which should not be overlooked. Any predictive performance costs are likely to be much smaller than perceived.
- Invest in experimentation. Randomised controlled experiments will generally provide the best measure of the effect of changes or interventions, but care must be taken to ensure they are well designed and executed. Human judgment and observational studies are inherently tainted by bias and confounding factors, and so are poor substitutes when it comes to picking winning ideas. A good experimentation culture has the potential to prevent bad ideas being adopted, and highlight great ideas that might otherwise have been missed.
Recent articles
Recent articles
More articles

Iran conflict fuelling compounding risks for Australian insurers
The 2026 Iran conflict is reshaping the risk outlook for general insurers. Understanding and adapting to this will determine who thrives.
Read Article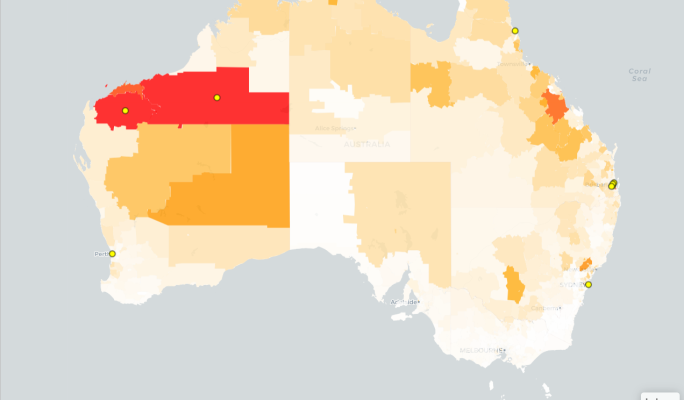

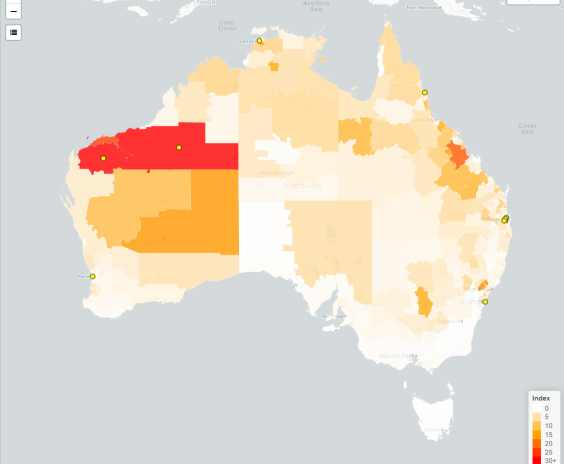
When the heat is on: Where Australia’s workers face greatest risk
Extreme heat is increasing workplace injury risk across Australia. Our new index identifies regions where workers face heat-related risk.
Read Article
Related articles
Related articles
More articles

How AI will be impacted by the biggest overhaul of Australia’s privacy laws in decades
Understand the key changes to the Privacy Act 1988 that may impact AI and how organisations who use AI can prepare for these changes.
Read Article

Well, that generative AI thing got real pretty quickly
Six months ago, the world seemed to stop and take notice of generative AI. Hugh Miller sorts through the hype and fears to find clarity.
Read Article